탐색적 자료분석
(머신러닝을 포함한) 통계적 추론에서는 양질의 자료가 필요합니다. 탐색적 자료분석(Exploratory Data Analysis; EDA)이란 본격적인 학습/분석을 실시하기 전, 기술 통계학적으로 자료의 특성을 파악하는 과정을 의미합니다. 탐색적 자료분석에서는 주로 변수의 분포, 이상점 존재 여부 등을 파악합니다.
탐색적 자료분석은 수치적인 값을 이용하거나 자료를 시각화하여 실시합니다. 자료의 수치적 요약값으로는 주로 평균, 중앙값, 분산과 같은 통계량을 사용하여 자료의 시각화로는 히스토그램, 산점도 등을 이용합니다.
자료의 시각화가 중요한 이유는 여러 가지가 있습니다. 대표적으로, 수치적으로 요약했을 때는 발견할 수 없는 정보들을 시각적으로 요약했을 때 확인할 수 있을 때가 많습니다. 가령, 다음의 그림은 수치적 요약값들이 거의 같지만 그 형태는 매우 다른 자료들의 예시를 보여줍니다.
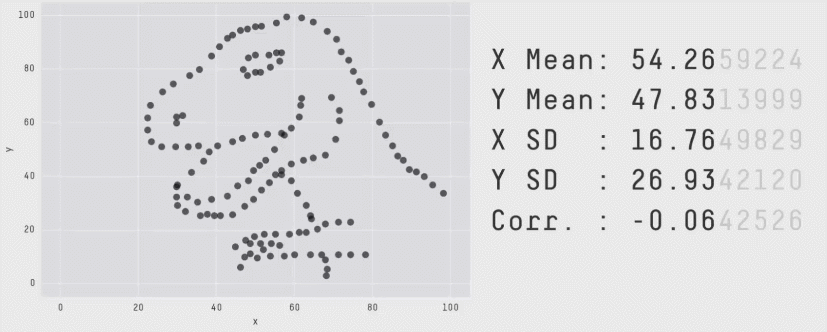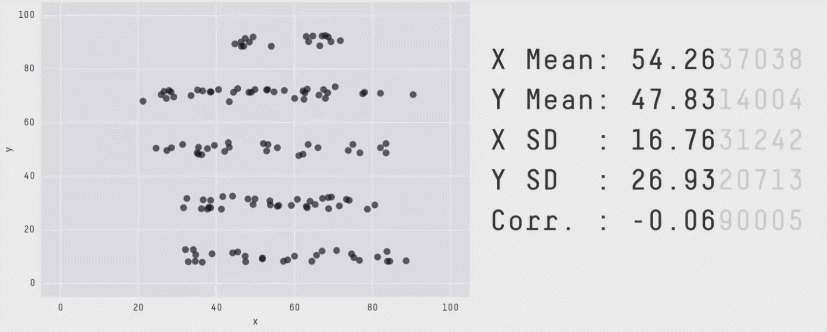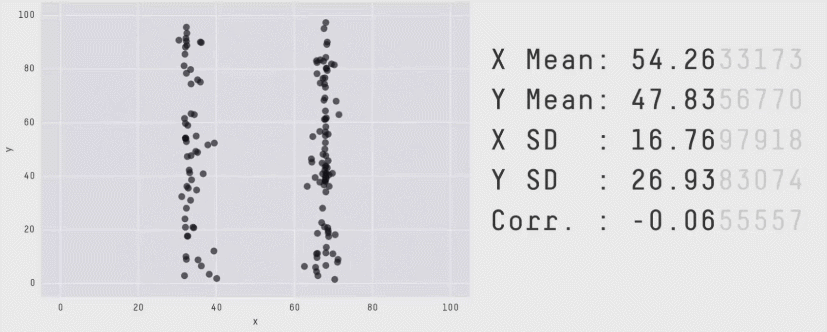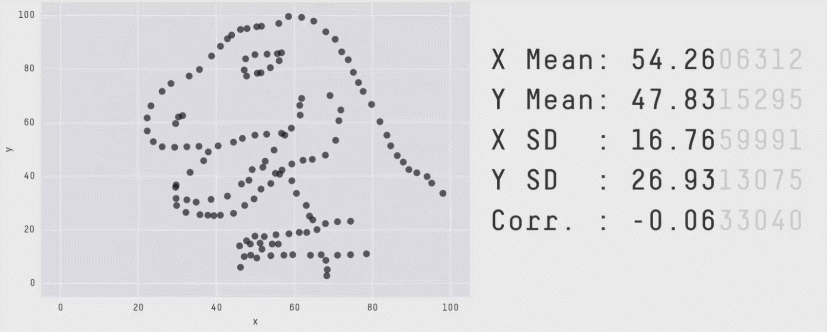
어떤 시각화 방법을 사용하느냐에 있어서도 해석이 달라질 수 있습니다.
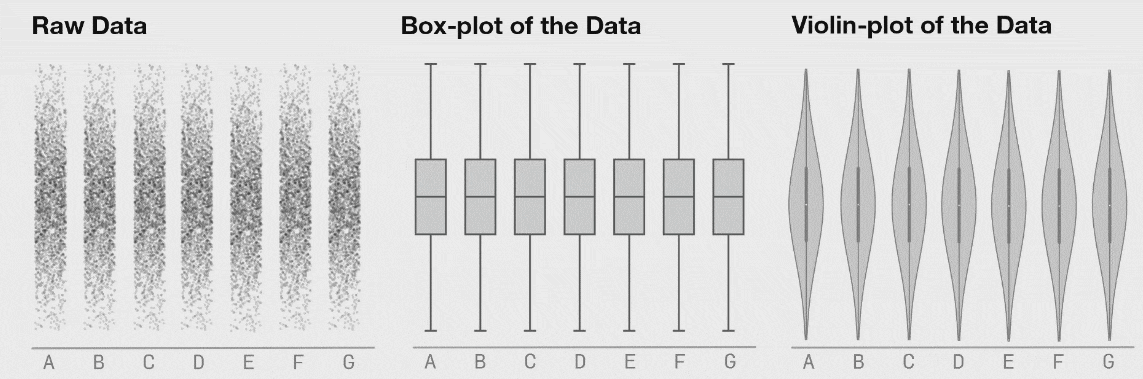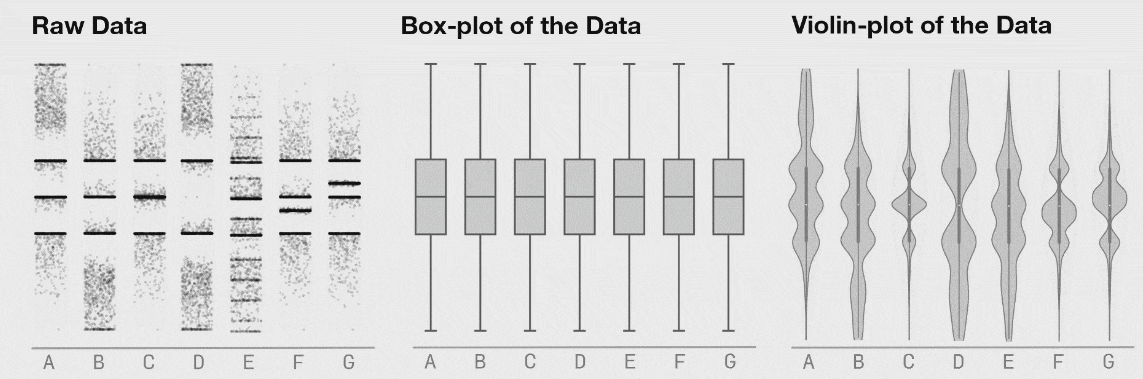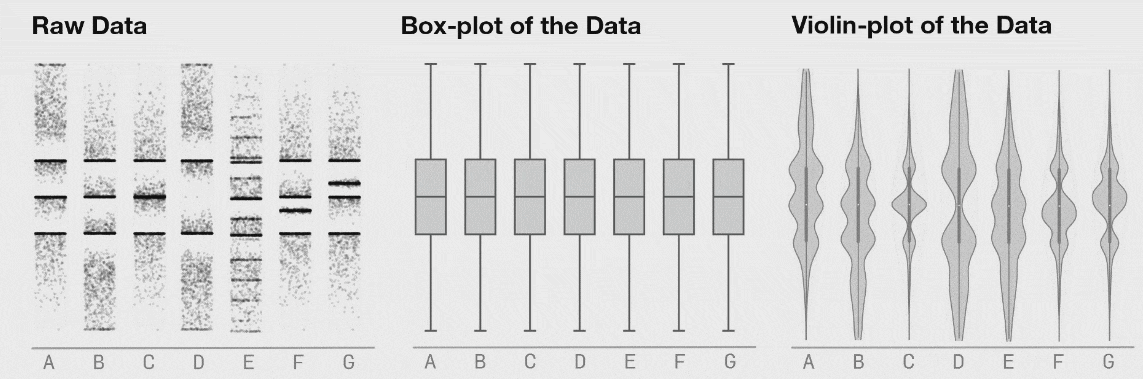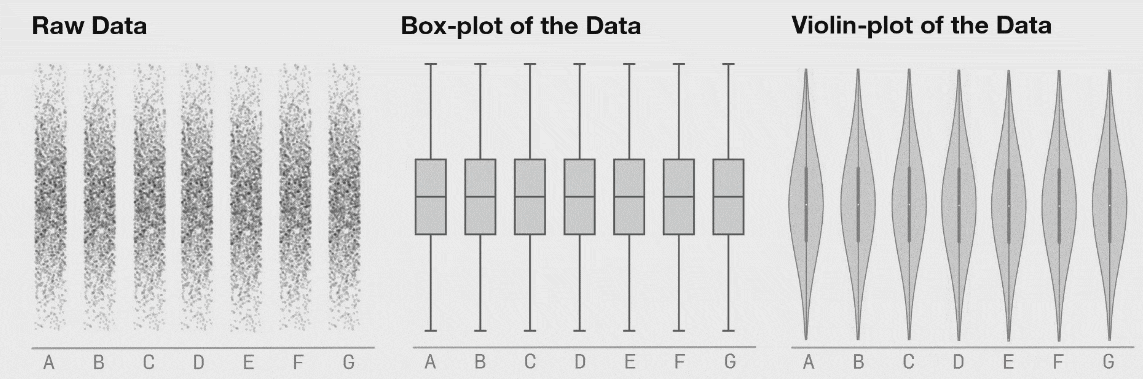
그렇다면 어떤 방법을 사용해야할까요? 정답은 없습니다. 여러분이 보여주고자 하는 목적에 맞는 방법을 선택하시면 됩니다.
R 패키지 소개
R에는 자료 분석에 특화되어있는 여러 가지 패키지들이 있습니다. 중 가장 유명한 것으로 Hardley Wickham이 개발한 tidyverse 패키지들이 있습니다.
tidyverse 패키지는 전처리에 필요한 패키지들을 정리하고 모아놓은 것으로, 대표적인 패키지로는 dplyr, tibble, tidyr, readr, readxl, ggplot2 등이 있습니다. 본 포스팅에서는 dplyr패키지와 ggplot2 패키지를 사용한 탐색적 자료분석방법에 대해 다루겠습니다.
dplyr 패키지
R에서 자료는 데이터 프레임으로 저장하여 사용합니다. dplyr는 데이터 프레임을 다루는 데 특화된 패키지로 파이썬의 pandas 패키지와 비슷한 일을 합니다.
dplyr 패키지는 C++ 코드로 작성되어 있기에 대용량의 자료를 효과적으로 분석할 수 있습니다. 먼저 다음과 같이 패키지를 불러오겠습니다.
| |
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
예제로, 내장되어있는 iris 자료를 사용하겠습니다.
먼저, filter 함수는 특정 조건을 만족시키는 데이터만 선별하여 출력하는 함수입니다. 다음과 같이, “setosa” 종에 대한 자료를 확인할 수 있습니다.
| |
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5.0 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
...
group_by 함수는 범주형인 변수를 이용해 데이터들을 그룹별로 묶는 역할을 합니다. 다음과 같이 종별로 붓꽃을 묶을 수 있습니다.
| |
# A tibble: 150 × 5
# Groups: Species [3]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
<dbl> <dbl> <dbl> <dbl> <fct>
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
7 4.6 3.4 1.4 0.3 setosa
8 5 3.4 1.5 0.2 setosa
9 4.4 2.9 1.4 0.2 setosa
10 4.9 3.1 1.5 0.1 setosa
# … with 140 more rows
mutate 는 작업하고자 하는 데이터 프레임을 기반으로 새 변수를 생성하여 원 데이터 프레임에 결합시키는 함수입니다.
여러 개의 열을 생성하여 붙일 수도 있습니다.
예를 들면, 다음과 같이 꽃받침의 길이를 반올림한 열을 만들 수 있습니다.
| |
Sepal.Length Sepal.Width Petal.Length Petal.Width Species sl_integer
1 5.1 3.5 1.4 0.2 setosa 5
2 4.9 3.0 1.4 0.2 setosa 5
3 4.7 3.2 1.3 0.2 setosa 5
4 4.6 3.1 1.5 0.2 setosa 5
5 5.0 3.6 1.4 0.2 setosa 5
6 5.4 3.9 1.7 0.4 setosa 5
7 4.6 3.4 1.4 0.3 setosa 5
8 5.0 3.4 1.5 0.2 setosa 5
9 4.4 2.9 1.4 0.2 setosa 4
10 4.9 3.1 1.5 0.1 setosa 5
...
summarise는 데이터프레임의 열에 접근하여 계산을 실시한 뒤 데이터프레임 형태로 반환합니다.
다음과 같이 꽃받침의 길이의 최솟값과 평균값을 계산할 수 있습니다.
| |
sl_min sl_mean
1 4.3 5.843333
dplyr 패키지는 이전의 결과를 이후의 입력으로 사용하는 파이프라인 함수 %>%를 지원합니다.
파이프라인을 이용하면 매우 효과적인 자료분석을 실시할 수 있습니다.
| |
# A tibble: 3 × 3
Species sl_min sl_mean
<fct> <dbl> <dbl>
1 setosa 4.3 5.01
2 versicolor 4.9 5.94
3 virginica 4.9 6.59
앞의 예제들을 통해 짐작할 수 있듯이 dplyr는 R에서 SQL과 비슷한 역할을 하는 패키지입니다. dbplyr 패키지와 같이 R에서 SQL을 연동하여 사용할 수 있는 패키지도 함께 제공되고 있습니다.
ggplot2 패키지
ggplot2 stands for grammar of graphics plot version 2
R의 기존 그래프는 점그래프(points), 선그래프(line), 막대그래프(histogram), 상자그림(boxplot) 등의 외형으로 분류되어 있으며, 각 목적에 맞는 함수를 호출함으로서 그래프를 그립니다. ggplot2은 그림을 외형으로 구분하지 않고 구성성분에 따라 층별(layer by layer)로 그립니다1. 즉, 그림을 그리는 과정을 절차에 따른 요소(components)로 나누어서 각 요소를 차례대로 쌓는 형식으로 구현합니다.

ggplot으로 그림을 그리는 방법을 간단히 소개하겠습니다. 먼저 패키지를 불러오겠습니다.
| |
먼저, data 인자를 사용해서 데이터와 그래프를 연결합니다.

| |

아직 아무것도 그리지 않은 레이어이므로 텅 비어있습니다.
미학요소(aesthetics, aes) 인자를 사용해 데이터의 변수와 그래프 플롯의 축 혹은 크기, 형태, 색상 등을 매핑(mapping)해야합니다.

| |
드디어 축이 생겼습니다!
geom_****() 함수를 통해 그래픽 요소를 추가할 수 있습니다.

geom 레이어를 추가하려면 + 연산자를 사용합니다.
다음과 같이 산점도를 추가할 수 있습니다. | |
ggplot2의 + 연산자는 이미 존재하는 ggplot 객체를 변형시킬 수 있습니다.
즉, “템플릿” 그래프 플롯을 생성하고, 다른 그래프 유형으로 쉽고 편리하게 바꿀 수 있습니다.
| |
다음과 같이 점을 추가할 수도 있고
| |
| |
| |
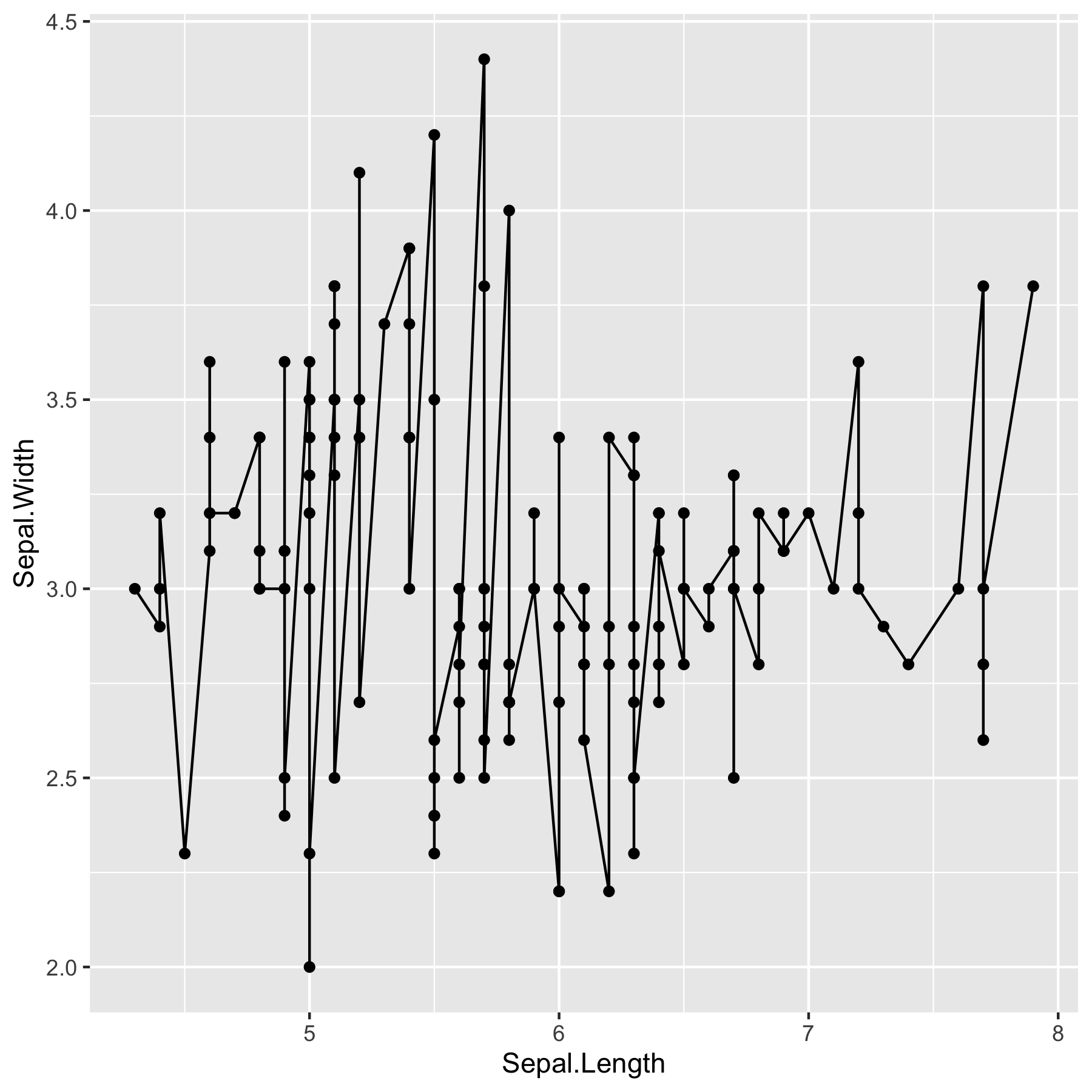
ggplot2의 장점은 aes를 이용해 미려한 그래프를 그릴 수 있다는 점입니다.
특히, 여러가지의 범주로 구성되어 있다면 color, size, alpha, shape 과 같은 함수 인자들을 통해 다양하게 표현이 가능합니다.
| |
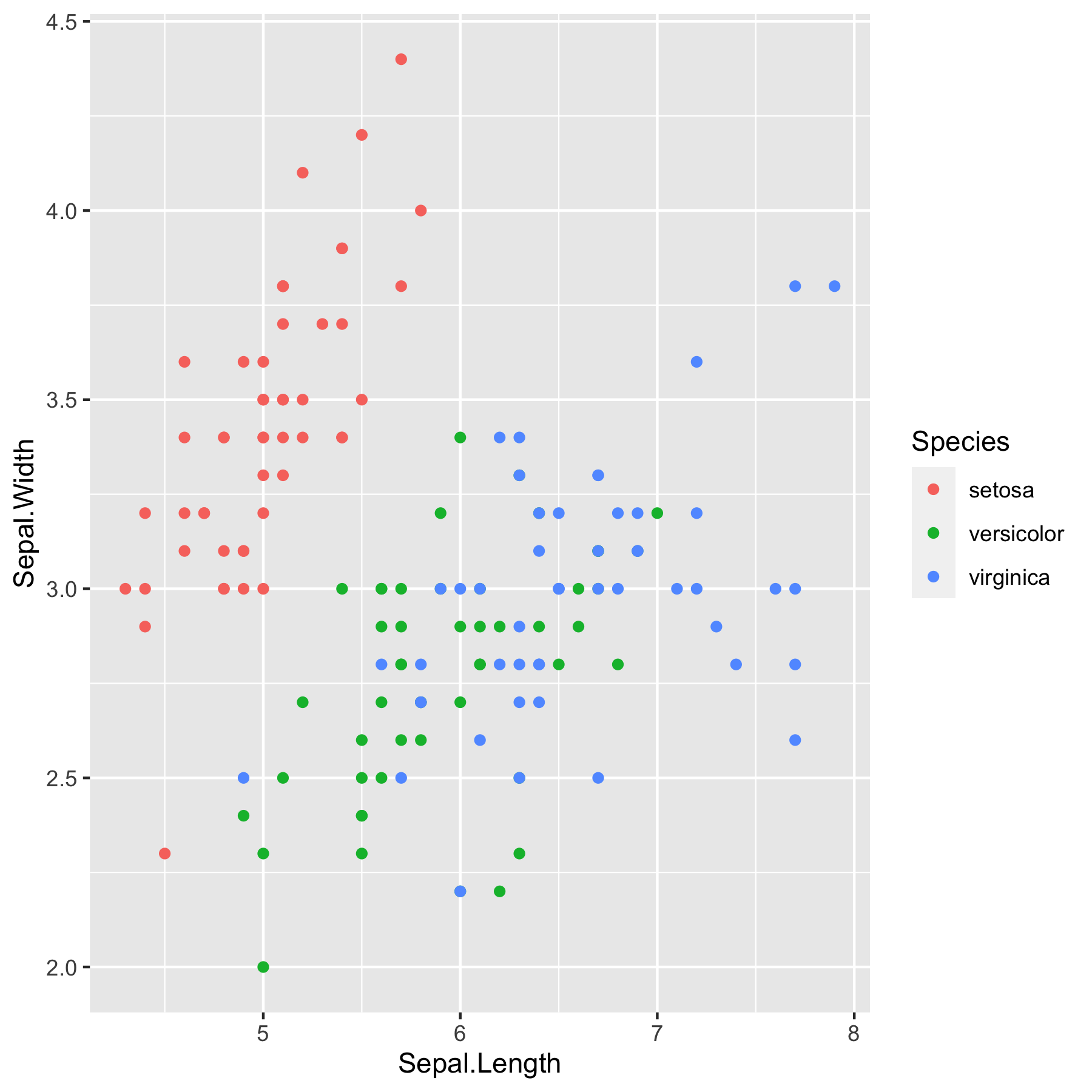
위의 패키지들을 따로 설치할 필요 없이 다음과 같이 설치하고, 불러올 수 있습니다.
| |
더 많은 기능들은 구글링과 치트시트를 참고하세요!
미세먼지 자료 분석
실제로 미세먼지 자료를 분석해보겠습니다.
미세먼지는 지름이 10㎛(마이크로미터, 1㎛=1000분의 1㎜) 이하의 먼지로 PM(Particulate Matter)10이라고 합니다. 자동차 배출가스나 공장 굴뚝 등을 통해 주로 배출되며 중국의 황사나 심한 스모그때 날아오는 크기가 작은 먼지에도 포함되어 있습니다. 미세먼지중 입자의 크기가 더 작은 미세먼지를 초미세먼지라 부르며 지름 2.5㎛ 이하의 먼지로서 PM2.5라고 합니다.
자료 불러오기
pmkw2018.Rdata에 2018년도 1분기 관악구의 대기오염 관측 자료를 저장하였습니다. 대기오염 자료는 에어코리아에서 다운로드 받아 직접 가공하였습니다. 다음 명령어를 통해 실습을 위한 자료를 불러오겠습니다.
| |
자료를 확인해보겠습니다.
| |
# A tibble: 1,819 × 13
지역 측정소코드 측정소명 측정일시 SO2 CO O3 NO2 PM10 PM25 주소 do gun
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr> <chr>
1 서울 관악구 111251 관악구 2018010101 0.006 0.3 0.013 0.024 35 22 서울 관악구 신림동길 14 서울 관악구
2 서울 관악구 111251 관악구 2018010102 0.006 0.4 0.009 0.029 38 27 서울 관악구 신림동길 14 서울 관악구
3 서울 관악구 111251 관악구 2018010103 0.006 0.4 0.007 0.034 34 22 서울 관악구 신림동길 14 서울 관악구
4 서울 관악구 111251 관악구 2018010104 0.007 0.3 0.006 0.034 30 17 서울 관악구 신림동길 14 서울 관악구
5 서울 관악구 111251 관악구 2018010105 0.007 0.3 0.005 0.037 28 15 서울 관악구 신림동길 14 서울 관악구
6 서울 관악구 111251 관악구 2018010106 0.007 0.3 0.004 0.037 27 18 서울 관악구 신림동길 14 서울 관악구
7 서울 관악구 111251 관악구 2018010107 0.007 0.4 0.002 0.043 29 18 서울 관악구 신림동길 14 서울 관악구
8 서울 관악구 111251 관악구 2018010108 0.007 0.6 0.001 0.046 32 16 서울 관악구 신림동길 14 서울 관악구
9 서울 관악구 111251 관악구 2018010109 0.007 0.6 0.002 0.048 32 19 서울 관악구 신림동길 14 서울 관악구
10 서울 관악구 111251 관악구 2018010110 0.009 0.5 0.005 0.041 26 15 서울 관악구 신림동길 14 서울 관악구
# … with 1,809 more rows
수치적으로 자료 요약하기
초미세먼지(PM2.5)의 관측치 개수, 평균, 표준편차, 최소값, 최대값은 다음과 같이 계산할 수 있습니다.
| |
앞서 소개한 dplyr의 summarise 함수를 이용할 수도 있습니다.
| |
# A tibble: 1 × 5
n mean sd min max
<int> <dbl> <dbl> <dbl> <dbl>
1 1819 35.2 23.5 2 192
비슷하게, 미세먼지(PM10)의 평균, 표준편차, 최소값, 최대값은 다음과 같이 계산할 수 있습니다.
| |
# A tibble: 1 × 4
mean sd min max
<dbl> <dbl> <dbl> <dbl>
1 49.2 26.3 5 205
초미세먼지의 분위수는 어떻게 계산할 수 있을까요? summary 함수를 사용하면 쉽게 계산할 수 있습니다.
여기서 Q1 (제1 사분위수; 1st Qu.)은 상위 50%, Median (제2 사분위수; Q2; 2st Qu.)는 중앙값, Q3 (제3 사분위수; 3rd Qu.)는 상위 25% 값을 의미합니다.
| |
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 18.00 29.00 35.24 46.00 192.00
- 초미세먼지 농도가 높은 시간대는 언제일까요?
dplyr패키지의 함수들을 사용해 계산할 수 있습니다.
| |
# A tibble: 82 × 2
date maxpm25time
<chr> <chr>
1 20180101 21
2 20180102 08
3 20180103 09
4 20180104 21
5 20180105 08
6 20180106 22
7 20180107 18
8 20180108 13
9 20180109 01
10 20180110 12
# … with 72 more rows
주로 새벽시간대에 초미세먼지 농도가 높게 나타난다는 것을 알 수 있습니다.
시각적으로 자료 요약하기
이번에는 시각적으로 자료를 요약해보겠습니다.
초미세먼지의 히스토그램을 그려보는 문제를 생각해보겠습니다. 가장 간단히, R의 히스토그램 함수를 이용할 수 있습니다.
| |
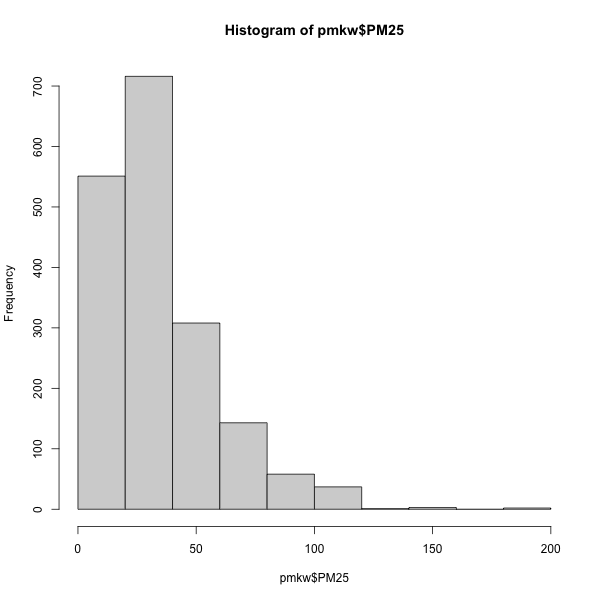
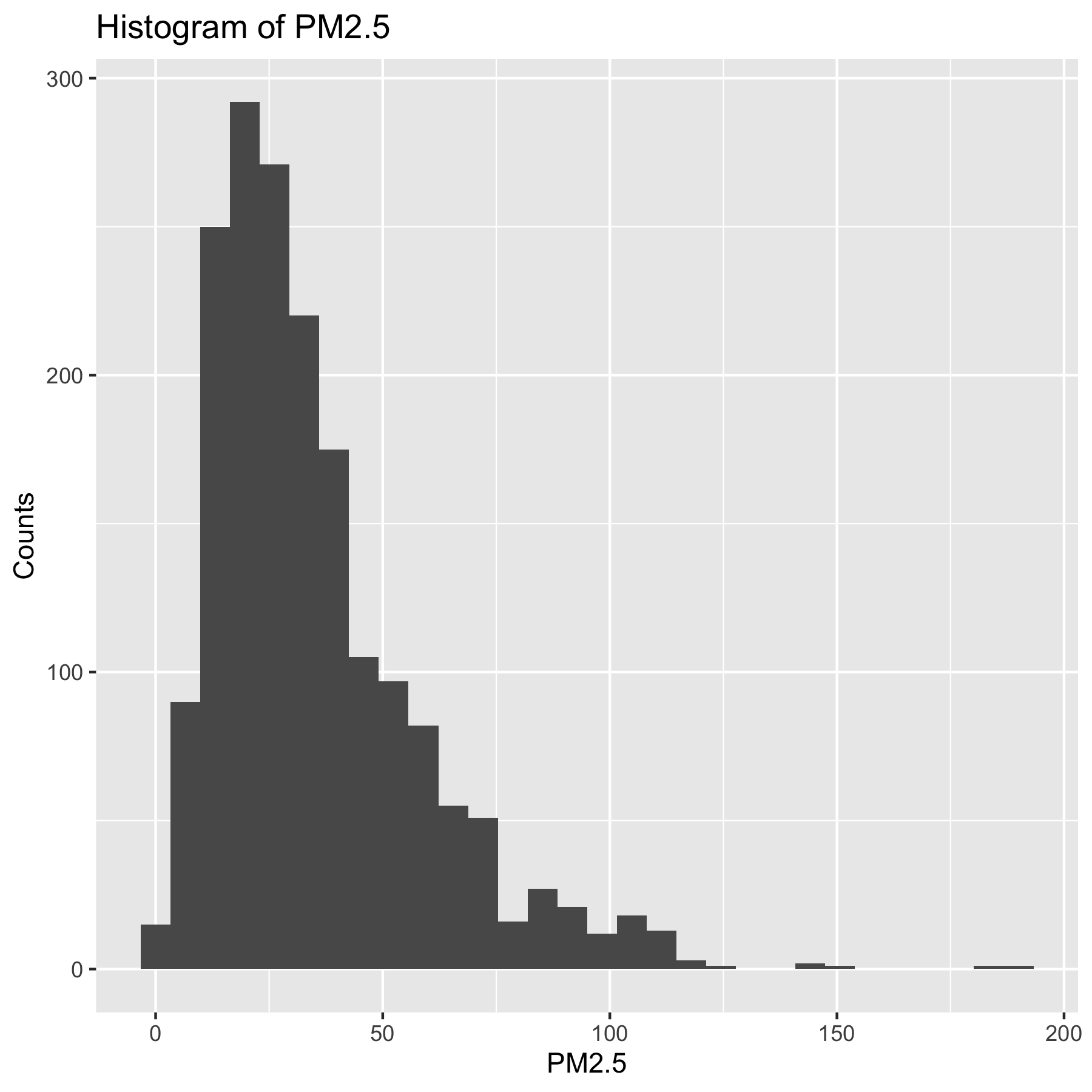
별로 예쁘지 않습니다. ggplot을 이용하면 다음과 같이 히스토그램을 그릴 수 있습니다.
| |
여기서 labs함수는 x축, y축, 제목 등에 작성되는 이름표(label)을 바꾸는 함수입니다.
다음과 같이 초미세먼지 농도와 미세먼지 농도를 한 그래프에 나타낼 수도 있습니다.
| |
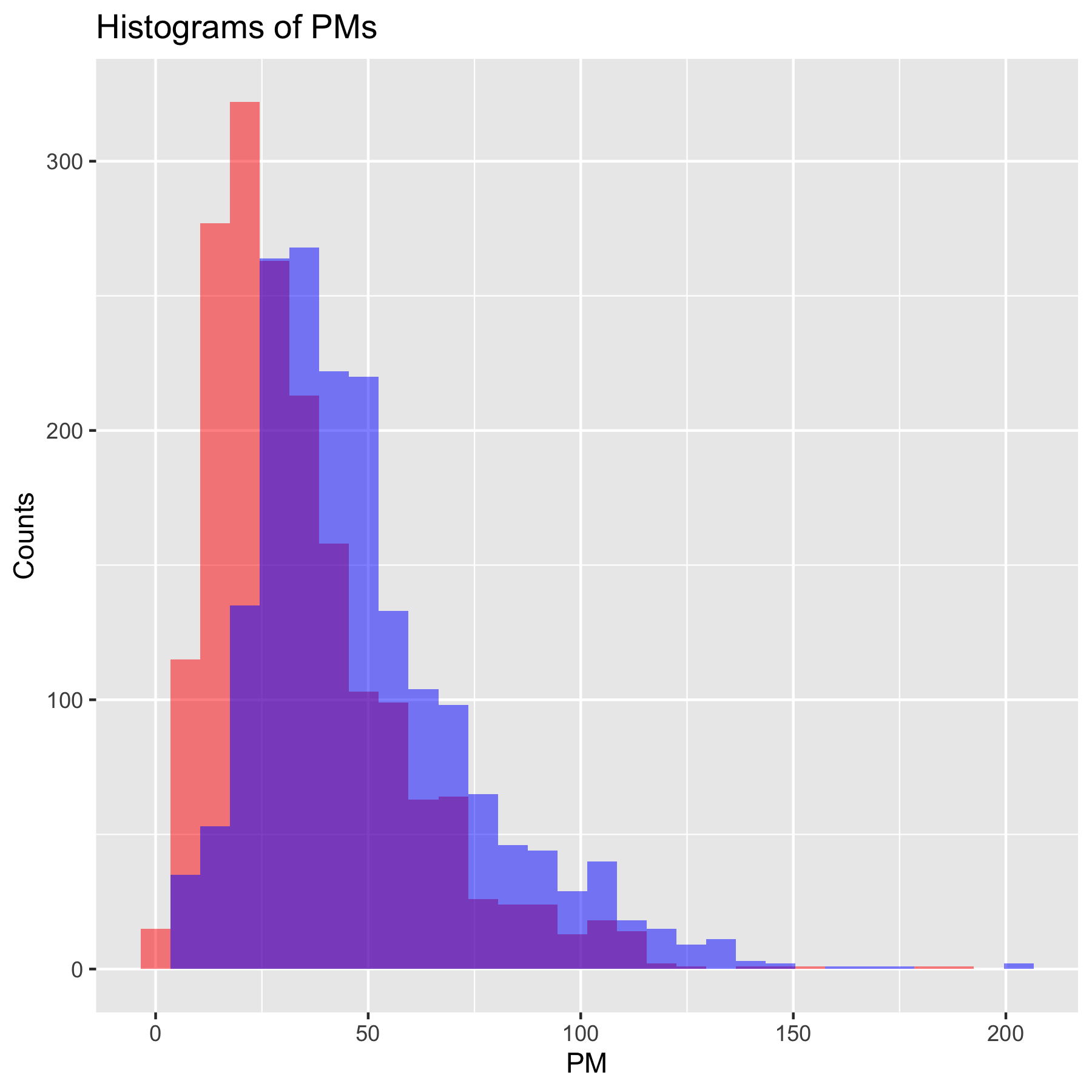
일부 극단적인 관측치들이 있음을 확인할 수 있습니다.
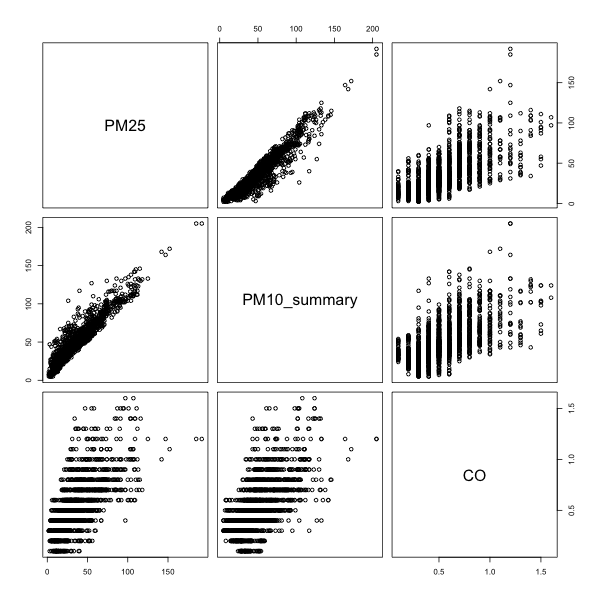
이번에는 미세먼지, 초미세먼지, 일산화탄소의 관계에 대해 알아보겠습니다.
R의 기본 plot 함수를 사용하면 다음과 같이 산점도를 그릴 수 있습니다.
| |
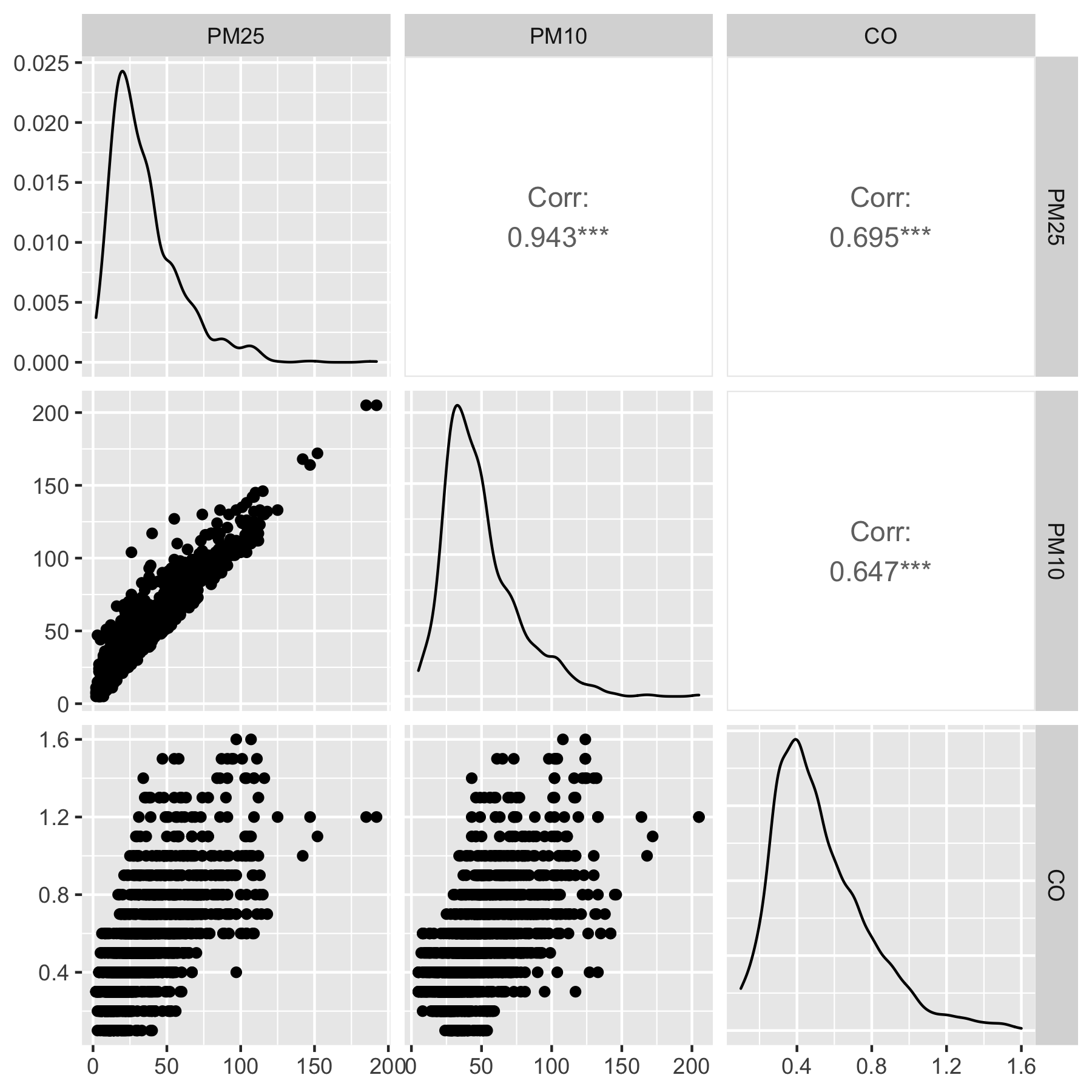
ggplot 패키지의 확장 패키지인 GGally 패키지의 ggpairs() 함수를 이용하면 더 미려하게 관계를 확인할 수 있습니다.
상관계수와 밀도함수를 추가적으로 제공합니다.
| |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
두 변수 사이의 상관계수는 cor() 함수를 통해서도 계산할 수 있습니다.
| |
[1] 0.9431976
모든 변수들이 왼쪽으로 치우친 분포들을 나타내고 있으며 미세먼지/초미세먼지 농도는 매우 밀접한 관계가 있다는 것을 확인할 수 있습니다. 만일 우리가 폐암발병률을 미세먼지와 초미세먼지 농도로부터 예측하는 모형을 만든다고 한다면, 두 가지 중 하나만을 설명변수로 사용하는 것이 더 좋을 것입니다.
참고자료
- https://englelab.gatech.edu/useRguide/introduction-to-ggplot2.html
- https://www.rstudio.com/resources/cheatsheets/
이 아이디어는 파이썬의 matplotlib 패키지에서도 사용합니다. ↩︎
comments powered by Disqus